Recently my latest project came with a strange requirement – I need to route IP packets from Linux kernel space to user space. In other word, I need to write a IP packets sniffer similar to tcpdump or wireshark.
The project does not have high data rate requirement. So I chose Python for some rapid prototyping to get a feel for the problem.
Sniffing with Scapy … Slowly
My past experience with Python is that it often comes with magical one-liner that just finish my job. And this time, Python did not disappoint me. My co-worker’s Google-Fu quickly found that the Scapy package has a sniff feature, and yes, it is a one-liner. 🙂
from scapy.all import * def pkt_callback(pkt): pkt.show() # debug statement sniff(iface="eth0", prn=pkt_callback, filter="ip", store=0)
On the first try, the above code functioned perfectly and I immediately saw all the incoming and outgoing packets as I browsed through different webpages to trigger http traffic.
So how about some stress test? For that, I browsed to the Ubuntu homepage and downloaded an Ubuntu ISO. The file is large, and the data rate is reasonably high for a quick test. Unfortunately, Scapy didn’t perform so well.
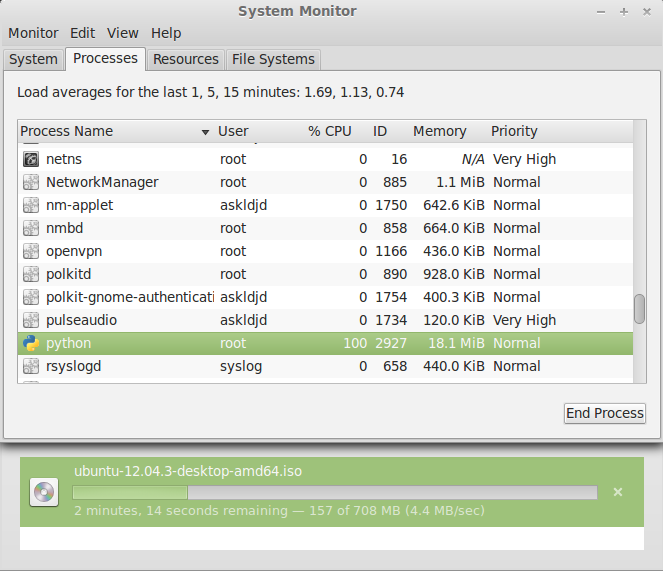
4.4 MBps data rate results in 100% usage.
It turns out that a ~4.4MBps (35Mbps) capture would consume close to 100% of my CPU. This is an unacceptable amount of overhead for just routing packets from kernel into user space.
Sniffing with Raw Socket
Since Scapy comes with too much overhead, the next step was to dive into a lower layer and implement a raw layer 2 socket. In user space, if an application creates a raw socket, the linux kernel will automatically forward a copy of the datagram of the same protocol number to the application. So if a layer 2 socket is implemented, the host application will receive all ethernet frames.
*Layer 2 socket is chosen because I need to sniff both incoming and outgoing packets on a network interface. L3 socket does not appear to provide this capabilities.
import socket, struct, os, array
from scapy.all import ETH_P_ALL
from scapy.all import select
from scapy.all import MTU
class IPSniff:
def __init__(self, interface_name, on_ip_incoming, on_ip_outgoing):
self.interface_name = interface_name
self.on_ip_incoming = on_ip_incoming
self.on_ip_outgoing = on_ip_outgoing
# The raw in (listen) socket is a L2 raw socket that listens
# for all packets going through a specific interface.
self.ins = socket.socket(
socket.AF_PACKET, socket.SOCK_RAW, socket.htons(ETH_P_ALL))
self.ins.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 2**30)
self.ins.bind((self.interface_name, ETH_P_ALL))
def __process_ipframe(self, pkt_type, ip_header, payload):
# Extract the 20 bytes IP header, ignoring the IP options
fields = struct.unpack("!BBHHHBBHII", ip_header)
dummy_hdrlen = fields[0] & 0xf
iplen = fields[2]
ip_src = payload[12:16]
ip_dst = payload[16:20]
ip_frame = payload[0:iplen]
if pkt_type == socket.PACKET_OUTGOING:
if self.on_ip_outgoing is not None:
self.on_ip_outgoing(ip_src, ip_dst, ip_frame)
else:
if self.on_ip_incoming is not None:
self.on_ip_incoming(ip_src, ip_dst, ip_frame)
def recv(self):
while True:
pkt, sa_ll = self.ins.recvfrom(MTU)
if type == socket.PACKET_OUTGOING and self.on_ip_outgoing is None:
continue
elif self.on_ip_outgoing is None:
continue
if len(pkt) <= 0:
break
eth_header = struct.unpack("!6s6sH", pkt[0:14])
dummy_eth_protocol = socket.ntohs(eth_header[2])
if eth_header[2] != 0x800 :
continue
ip_header = pkt[14:34]
payload = pkt[14:]
self.__process_ipframe(sa_ll[2], ip_header, payload)
#Example code to use IPSniff
def test_incoming_callback(src, dst, frame):
#pass
print("incoming - src=%s, dst=%s, frame len = %d"
%(socket.inet_ntoa(src), socket.inet_ntoa(dst), len(frame)))
def test_outgoing_callback(src, dst, frame):
#pass
print("outgoing - src=%s, dst=%s, frame len = %d"
%(socket.inet_ntoa(src), socket.inet_ntoa(dst), len(frame)))
ip_sniff = IPSniff('eth3', test_incoming_callback, test_outgoing_callback)
ip_sniff.recv()
So how’s the performance this time around? It turned out to be surprisingly fast.
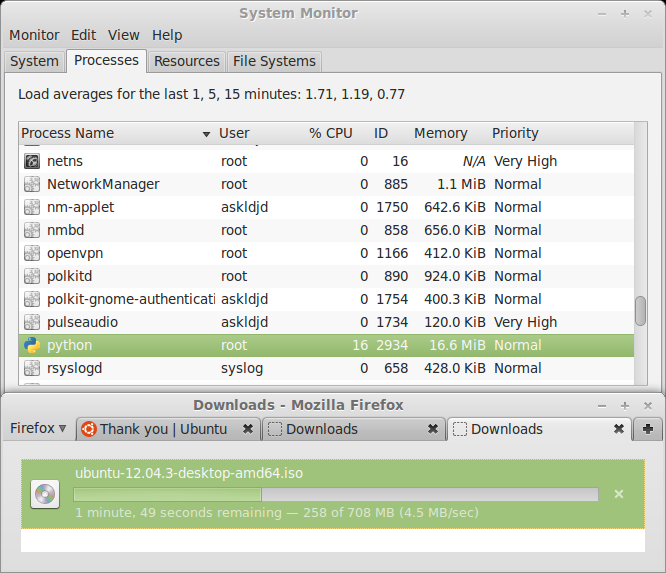
Same as before, but only use 16% of CPU.
With the same data rate, the previous 100% CPU consumption now goes down to only 16%.
This is more than fast enough for my application. Mission Accomplished!
Final Thoughts
If the Python raw socket was still too slow, the next step would be to re-write the raw socket in C.
Scapy comes with a lot of overhead in practice as a live packet sniffer. If you don’t need all the power of Scapy, an IP sniffer can be easily implemented in Python raw socket and provides fairly reasonable performance.
Source
Binding a raw socket requires root permission. Therefore, the scripts need to run under root permission.
scapy_sniff.py – IP sniffer using Scapy
ip_sniff.py – IP sniffer using Python raw socket
Hardware
All tests were run under Mint Linux 15 VirtualBox VM with Window 7 as host.





{kind=link}