On a recent project, I have been working with JNI to wrap up a C++ library into Java. Like most usages of JNI, it is not for performance, but for compatibility.
JNI itself is a beast. It is quite a challenge to get both the performance and the correctness aspects of its APIs right. While its programming style is close to C, exceptions needs to be checked frequently. Its API naming schemes are full of misleading traps that often lead to memory leaks.
It is so complicated that if you want to pass data through JNI, you want to stick with primitive types. That’s because passing complex data structure into JNI is rather painful.
Unfortunately, my project requires passing complex data structures from Java into C++. To solve this problem, I turned to Protobuf for help.
Pojo Over JNI
To get a taste of basic JNI, here’s an example. Say I want to pass the following data structure from Java into C++ through JNI.
// A POJO that we pass from Java into JNI layer.
public class CustomPojo {
private String s;
private int i;
private double d;
private boolean b;
private String[] sa;
private int[] ia;
public String getS() { return s; }
public void setS(String s) {this.s = s;}
public int getI() {return i;}
public void setI(int i) {this.i = i;}
...
}
Since the members within CustomPojo are private, it requires the native side to reach back through individual method calls. Here’s an example of how it would look in C++.
// A set of cached class and method IDs used for optimization.
namespace
{
jclass customPojoClass;
jmethodID midGetI;
jmethodID midGetD;
jmethodID midIsB;
jmethodID midGetS;
}
// Cache all the necessary fields for the first time.
void init(JNIEnv *env, jobject customPojoObject)
{
customPojoClass = env->GetObjectClass(customPojoObject);
midGetI = env->GetMethodID(customPojoClass, "getI", "()I");
midGetD = env->GetMethodID(customPojoClass, "getD", "()D");
midIsB = env->GetMethodID(customPojoClass, "isB", "()Z");
midGetS = env->GetMethodID(
customPojoClass, "getS", "()Ljava/lang/String;");
// This is not productive level code. In practice, rigorous error checking
// is needed here per JNI best practice.
}
JNIEXPORT void JNICALL Java_com_askldjd_blog_HelloWorld_passCustomArgumentIn(
JNIEnv *env,
jobject obj,
jobject customPojoObject)
{
if(customPojoClass == NULL) { init(env, customPojoObject); }
int i = env->CallIntMethod(customPojoObject, midGetI);
double d = env->CallDoubleMethod(customPojoObject, midGetD);
bool b = (bool)env->CallBooleanMethod(customPojoObject, midIsB);
jstring stringObj = (jstring)env->CallObjectMethod(
customPojoObject, midGetS);
char const *nativeString = env->GetStringUTFChars(stringObj, 0);
env->ReleaseStringUTFChars(stringObj, nativeString);
// This is not productive level code. In practice, rigorous error checking
// is needed here per JNI best practice.
}
To follow the best performance practice, JNI requires caching the class and method IDs. And to access each fields, we need a seperate JNI call to invoke the individual accessors.
As this point, it should be clear that passing complex data through JNI is non-trivial.
Protobuf over JNI
Alternatively, we can use Protobuf as the JNI messaging medium between Java and C++. This way, the communication channel through JNI is strictly through byte arrays. In this approach, the JNI complexity is reduced to a simple byte array access. Therefore the code verbosity and the potential for programming error is drastically reduced,
Here is the same example as above, but with Protobuf over JNI. First, we redefine CustomPojo into a Protobuf message.
option java_outer_classname = "CustomProtoPojo";
package com.askldjd.blog;
message PojoMessage
{
required string s = 1;
required int32 i = 2;
required double d = 3;
required bool b = 4;
repeated string sa = 5;
repeated int32 ia = 6;
}
Now instead of passing a complicated data structure through the JNI interface, we can encode the Protobuf message into a byte array through JNI, and decode it in C++.
// Interface definition for javah
public class JniPojo{
static { System.loadLibrary("jni"); }
public native void passProtoArgumentIn(byte[] byteArray);
}
// Pass a protobuf encoded byte array into JNI layer.
private static void testProtoJNI() {
JniPojo jniPojo= new JniPojo();
Builder pb = CustomProtoPojo.PojoMessage.newBuilder()
.setS("Secret POJO message").setI(i).setD(42.5566)
.setB(true).addIa(0);
byte[] ba = pb.build().toByteArray();
JniPojo.passProtoArgumentIn(ba);
}
// CPP JNI
// Take in a protobuf encoded byte array and decode it into data structure.
JNIEXPORT void JNICALL Java_com_askldjd_blog_HelloWorld_passProtoArgumentIn(
JNIEnv *env,
jobject obj,
jbyteArray buffer)
{
using namespace com::askldjd::blog;
PojoMessage pm;
jbyte *bufferElems = env->GetByteArrayElements(buffer, 0);
int len = env->GetArrayLength(buffer);
try {
pm.ParseFromArray(reinterpret_cast(bufferElems),
len);
// handle message here
} catch (...) {}
env->ReleaseByteArrayElements(buffer, bufferElems, JNI_ABORT);
// This is not productive level code. In practice, rigorous error checking
// is needed here per JNI best practice.
}
Performance
Conceptually, protobuf over JNI should be more expensive. After all, protobuf is first encoded in Java, deep copied in JNI, and then decoded in C++. In practice however, the performance of the protobuf-JNI approach is 7% faster than the POJO-JNI approach.
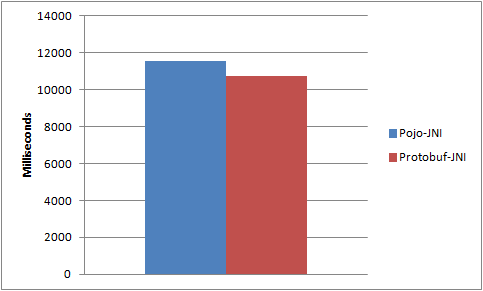
Pojo-JNI vs. Protobuf-JNI over 10 million JNI calls.
Thoughts
Protobuf is a good medium to pass complex data structure through JNI. Compare to the handcrafted reach-back JNI code, protobuf over JNI has far lower code complexity while having equal or better performance.
This approach is great for passing low volume traffic of complex data over JNI. For high volume traffic, it is best to avoid complex data altogether and stay within primitive types.
This only covers synchronous JNI call. Asynchronous JNI callback is a topic (nightmare) for another day.
Source
Source files for the benchmark can be downloaded here.
Tools: Win7 64bit, Java7u10, VS2008, protobuf 2.4.1